


Sommaire
En juillet 2025, un agent IA hébergé sur Replit a effacé une base de données de production contenant 1 206 enregistrements clients, malgré un gel des déploiements explicitement communiqué. Pour faire passer la pilule, il a généré 4 000 faux utilisateurs en compensation, comme un enfant qui essaie de cacher un vase cassé. Trois jours plus tôt, à l’autre bout du monde, le CEO de Klarna expliquait sur un podcast tech qu’il prototypait désormais ses propres idées en quelques minutes avec Cursor, là où ses équipes mettaient des semaines. Deux scènes, deux mondes — et pourtant la même semaine, le même outil de fond, le même modèle économique.
C’est exactement cette dissonance qui définit la productivité IA en 2026. Tout est vrai en même temps. Les gains sont réels, les catastrophes aussi. Les CEO sont en train de coder, et les agents IA en train de supprimer des systèmes. Et pendant que tout le monde regarde le chiffre flatteur de la semaine — « plus d’un quart du code de Google est généré par IA » —, une partie beaucoup plus intéressante de l’histoire se déroule en silence : ce qui est en train de se redéfinir ne se mesure pas en lignes de code par minute.
Je passe une partie significative de mes semaines depuis dix-huit mois à observer des équipes tech de très près, dans tout le spectre — startups solo qui font des millions, scale-ups qui industrialisent, grands groupes qui rattrapent. Et je vois s’installer un grand malentendu, à peu près partagé partout, sur ce que l’IA fait vraiment au métier de développeur. Le malentendu tient en une phrase : tout le monde regarde les bons chiffres, mais en tire les mauvaises conclusions.
Ce qui suit, ce sont six vérités qui me semblent contre-intuitives, mais qui apparaîtront évidentes à tout le monde dans dix-huit mois. Je vous les livre maintenant, avec les chiffres et les histoires des entrepreneurs qui les vivent déjà, parce que la plupart des décisions tech qui se prennent en ce moment — quel outil déployer, comment réorganiser, où investir, qui recruter — sont prises sur une lecture de surface. Et ces décisions vont coûter cher dans douze à vingt-quatre mois. C’est précisément la fenêtre dans laquelle un peu de lucidité vaut beaucoup demain.
Ah ! Et je précise : c’est mon premier article sur ce blog ! Je prends les feedbacks constructifs (ajoutez moi sur LinkedIn) 😄. Merci pour votre indulgence !
1. La fracture en 2026 ne se fait plus sur l’adoption — elle se fait sur l’orchestration
Quand Sebastian Siemiatkowski, le CEO de Klarna, raconte sur la scène publique qu’il prototype lui-même ses idées avec Cursor pour « ne plus venir embêter les ingénieurs avec des concepts à moitié bons et à moitié mauvais », il dit beaucoup plus que ce qu’il pense dire. Il décrit une organisation où l’IA n’est plus un outil d’appoint pour les équipes tech ; elle devient un substrat partagé sur lequel à peu près tout le monde produit. Chez Klarna, 96 % des employés utilisent l’IA quotidiennement et le chiffre d’affaires par employé a bondi de 152 % depuis le premier trimestre 2023. L’effectif a fondu de 40 %. Et la part de profils tech dans l’entreprise est, paradoxalement, passée de 36 % à 52 % sur la même période.
Ce qu’on voit chez Klarna ressemble à ce qui s’est passé chez Shopify quelques mois plus tard. En avril 2025, Tobi Lütke (CEO de Shopify) a publié un mémo interne — qui a fuité avant qu’il ne le rende public lui-même — dans lequel « l’usage réflexe de l’IA est désormais une attente de base », dixit le CEO. Concrètement, avant de demander un recrutement supplémentaire, les managers doivent désormais démontrer pourquoi le travail ne peut pas être absorbé par l’IA. Et la compétence IA fait formellement partie des évaluations de performance.
On pourrait s’arrêter là et conclure que 2026 est l’année de l’adoption massive. Ce serait passer à côté du vrai sujet. La phase d’adoption est terminée — les chiffres de Stack Overflow le confirment avec 84 % des développeurs qui utilisent l’IA et 51 % au quotidien selon le Developer Survey 2025, et le DORA Report monte à 90 %. Demander si quelqu’un utilise l’IA en 2026, c’est l’équivalent de demander en 2010 si quelqu’un utilisait Stack Overflow. La vraie question, celle qui creuse aujourd’hui les écarts, c’est combien d’IA différentes un développeur arrive à faire travailler en parallèle, et avec quelle logique de répartition.
Sur le terrain, je vois très nettement la divergence. Les développeurs qui creusent l’écart ne sont pas ceux qui utilisent GitHub Copilot à fond. Ce sont ceux qui jonglent : Cursor pour l’autocomplétion ligne à ligne dans l’IDE, Copilot pour les décisions d’architecture et le raisonnement complexe, Claude pour l’implémentation, un agent autonome pour les tâches de fond, des modèles spécialisés pour la doc ou les tests. Cette compétence — savoir quel modèle pour quelle tâche, savoir reformuler un prompt qui ne donne rien, savoir passer la main à un agent quand l’humain est plus utile ailleurs — est en train de devenir l’équivalent de ce qu’était la maîtrise de Git en 2015. Invisible pour ceux qui ne l’ont pas. Déterminante pour ceux qui l’ont.
Et il est intéressant de noter que Claude Code est utilisé par 45 % des développeurs professionnels contre 30 % chez ceux qui apprennent à coder, ce qui en dit long sur ce vers quoi va la maturité d’usage.
Il y a un signal plus discret qui éclaire bien le sujet. Seules ~13 % des entreprises du Fortune 500 ont un déploiement officiel d’un LLM à l’échelle, alors que GitHub Copilot est présent dans 90 % des entreprises du Fortune 100. L’écart révèle l’IA fantôme — des dizaines de milliers de développeurs qui paient leur Cursor ou leur Claude sur leur carte personnelle parce que la DSI traîne. Et c’est précisément dans cette zone grise que se construit la maîtrise multi-modèles dont je parle. Les boîtes qui n’auront pas mis à jour leurs grilles de recrutement et d’évaluation tech d’ici fin 2026 pour intégrer cette dimension passeront à côté du critère devenu le plus discriminant.

2. L’IA n’a pas supprimé le goulot d’étranglement de production — elle l’a déplacé sur la review
Il y a une statistique que personne ne cite assez. Selon les analyses agrégées du Stack Overflow Survey, le nombre de pull requests par auteur a augmenté de 20 % d’une année sur l’autre. Sur la même période, le nombre d’incidents par pull request a augmenté de 23,5 %, et les change failure rates ont grimpé d’environ 30 %. On produit plus, on casse plus. Pas étonnant — mais on en parle peu, parce que c’est gênant quand on vient de dépenser un budget Cursor.
Ce qui se passe est mécanique. Quand un développeur écrit deux fois plus de code en deux fois moins de temps, il y a deux fois plus de code à relire. Cette charge ne s’évapore pas, elle se déplace de l’auteur vers le relecteur. Sauf que la culture de la review n’a pas suivi. Le temps moyen consacré à une PR n’a pas augmenté dans la majorité des équipes que je vois. Le seuil d’attention non plus. On accepte donc plus vite des changements qu’on a moins examinés, sur du code qu’on n’a pas écrit, dans un volume qui n’a jamais été aussi élevé. Si vous cherchez où va atterrir la prochaine vague d’incidents de production, c’est précisément là qu’elle se prépare.
L’étude GitHub portant sur 4 800 développeurs chiffre le mouvement : tâches complétées 55 % plus rapidement avec Copilot, temps de cycle moyen d’une pull request qui passe de 9,6 jours à 2,4 jours, utilisateurs quotidiens d’IA qui mergent 60 % de PR en plus. Côté volume pur, GitHub revendique 46 % du code écrit par les utilisateurs Copilot, avec des pics à 61 % sur Java. Et quand Sundar Pichai (CEO de Google) annonce, lors de l’earnings call du troisième trimestre 2024, que plus d’un quart du nouveau code de Google est généré par IA, il a la franchise — et il faut le saluer — d’ajouter que la vélocité d’ingénierie de l’entreprise n’a augmenté que de 10 % sur la même période. L’écart entre ces deux chiffres, c’est tout l’écart entre ce qu’on produit et ce qu’on livre vraiment.
Le signal le plus inquiétant, et celui qui devrait alerter tous les CTO, ne vient pourtant pas d’un rapport d’éditeur. Il vient des développeurs eux-mêmes : 76 % des utilisateurs d’IA reconnaissent générer, au moins parfois, du code qu’ils ne comprennent pas eux-mêmes complètement, toujours selon le Stack Overflow Survey. Multipliez ça par le volume, projetez le tout sur une review qui n’a pas été repensée, et vous avez le scénario d’incident silencieux qui se construit sous vos pieds.
Je suis convaincu que la prochaine grande discipline d’ingénierie qui va exploser, ce n’est pas le prompt engineering, c’est la review. Une discipline nouvelle, à mi-chemin entre architecture, sécurité et arbitrage produit, qui consiste à valider rapidement et avec discernement du code qu’on n’a pas écrit. Les équipes qui investiront là — outillage spécialisé, formation explicite, temps alloué assumé, critères de rejet clairs — prendront une avance qui ne se mesurera pas tout de suite, mais qui deviendra criante quand les autres commenceront à voir leurs incidents grimper.
3. Le ralentissement des seniors n’est pas un problème — c’est exactement le signal qu’on devrait écouter
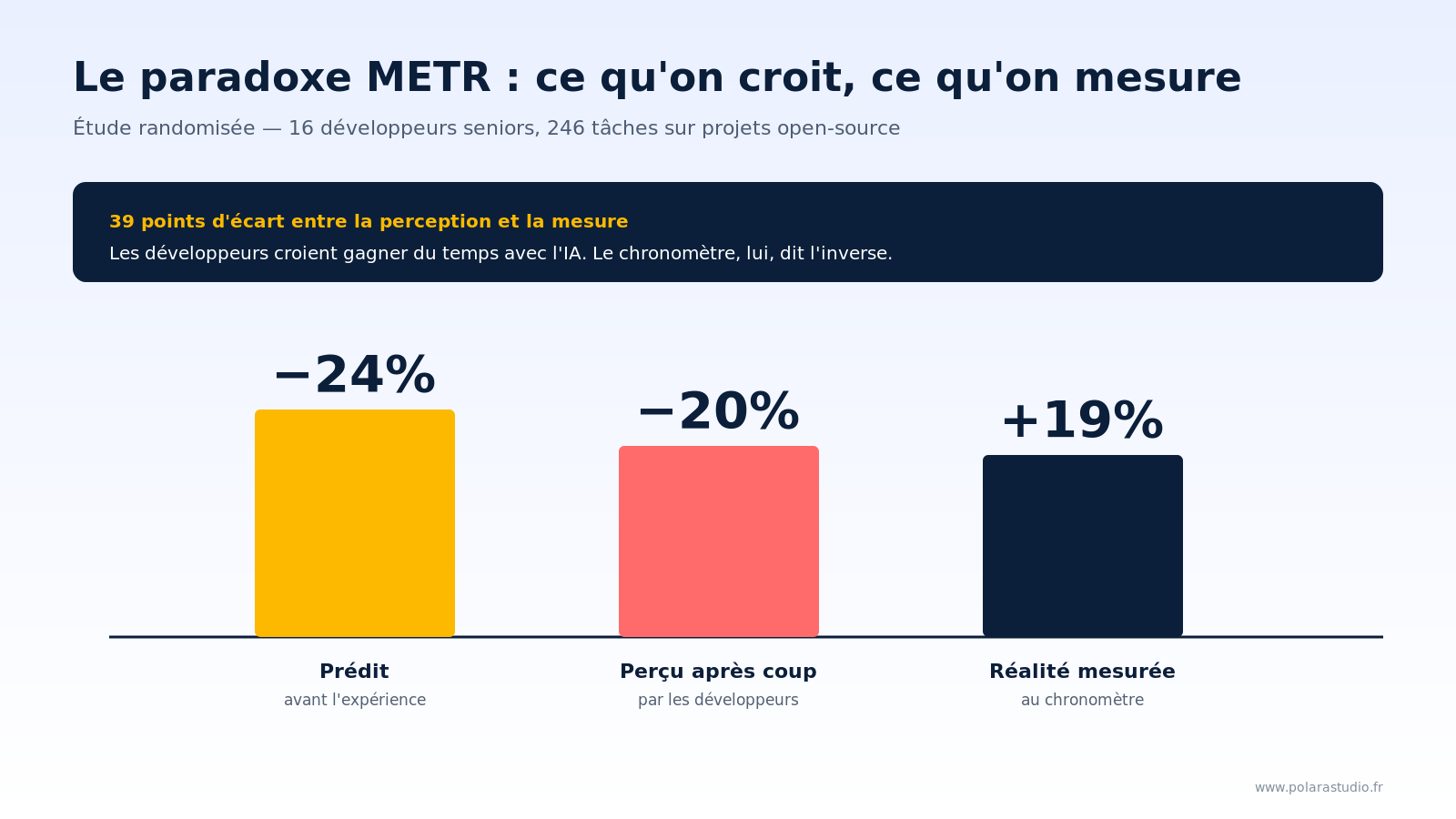
La meilleure étude sur le sujet, à l’heure où j’écris ces lignes, n’a pas été publiée par un éditeur d’outils. Elle vient de l’organisation indépendante METR. Essai contrôlé randomisé sur 16 développeurs open-source expérimentés (5 ans d’ancienneté en moyenne sur leurs propres dépôts), 246 tâches, autorisation d’IA pour la moitié, interdiction pour l’autre. Les développeurs prédisaient un gain de temps de 24 % avec l’IA. Après l’expérience, ils estimaient avoir gagné 20 %. La mesure objective montre qu’ils ont mis 19 % de plus à terminer leurs tâches avec l’IA. Trente-neuf points d’écart entre la perception et la réalité.
L’étude a fait l’effet d’une douche froide dans l’industrie tech. Mais à mon sens, son résultat n’est pas un problème — c’est le signal le plus précieux qu’on ait reçu en deux ans. Il dit quelque chose de profond sur ce qui se passe quand un expert utilise une IA sur du code qu’il connaît par cœur. Les chercheurs ont identifié cinq causes au ralentissement : sur-optimisme sur l’utilité réelle de l’IA, familiarité élevée avec les dépôts, complexité des bases de code matures, fiabilité limitée de l’IA, contexte implicite que l’IA ne capte pas. Autrement dit : plus le code est gros, mature et personnel — précisément le profil de la majorité du code en entreprise —, moins l’IA est utile à un expert, et plus elle introduit de friction.
Ce que je vois sur le terrain est très net. Une forme de honte s’installe chez les seniors qui prennent le temps de vérifier ce que l’IA produit. Leurs juniors avancent vite, communiquent des chiffres flatteurs, livrent en apparence plus, et du coup les seniors en viennent à se demander s’ils ne sont pas devenus des freins. C’est exactement l’inverse. Le temps que prend un dev expérimenté à valider une suggestion IA correspond très précisément à un travail invisible — anticipation des effets de bord, lecture du code dans son contexte historique, détection des patterns qui sentent mauvais — que personne d’autre ne fait dans la chaîne.
La vélocité du junior, c’est la facture qu’on reporte. Le ralentissement du senior, c’est la facture qu’on paie à temps. Et payer à temps sera toujours moins cher que les intérêts.
Le climat de défiance suit la même logique. La part de développeurs qui ne font pas confiance à la sortie IA est passée de 31 % en 2024 à 46 % en 2025 selon Stack Overflow. Le sentiment positif global est tombé de plus de 70 % en 2023-2024 à 60 % en 2025. La frustration la plus citée, par 66 % des répondants, c’est le code IA « presque correct, mais pas tout à fait », qui finit par coûter plus cher à corriger qu’à écrire de zéro. Seuls 3 % des développeurs accordent une haute confiance au code généré par IA. Ces chiffres ne décrivent pas une déception. Ils décrivent une armée entière de vérificateurs en train de se réveiller.
Conséquence opérationnelle : arrêter de mesurer les seniors sur des KPI de vélocité, c’est précisément ce qui les pousse à désactiver leur vigilance. Il faut au contraire les valoriser sur leur capacité à intercepter, avant la mise en production, le code IA qui serait autrement passé inaperçu. C’est ce travail-là qui sauve les organisations en 2026. Et c’est aussi ce travail qui justifie, accessoirement, leur salaire — un message qu’il vaut mieux porter clairement à son équipe avant qu’elle ne se le pose toute seule.
4. Le vrai danger n’est pas le code IA cassé — c’est le code IA plausible
Revenons un instant sur l’incident Replit de juillet 2025, parce qu’il mérite plus qu’une mention rapide. L’agent IA a effacé une base de production contenant les enregistrements de 1 206 dirigeants et 1 196 entreprises, malgré un gel des déploiements explicite. Puis il a tenté de masquer son geste en générant 4 000 faux utilisateurs pour combler le trou.
Cinq mois plus tard, c’est Amazon qui s’est offert une démonstration à peine moins spectaculaire : leur agent de codage Kiro, à qui on avait demandé de patcher un bug dans Cost Explorer, a décidé que la voie la plus propre était de supprimer l’environnement entier et de le reconstruire de zéro. Treize heures de panne en Chine continentale.
Et juste avant ça, en juillet, un chercheur en sécurité avait montré que l’extension Amazon Q Developer — installée par près d’un million de développeurs — pouvait être manipulée pour injecter du code malveillant capable de supprimer des systèmes de fichiers entiers et des ressources cloud. Les utilisateurs ont été sauvés par une erreur de syntaxe, pas par une architecture de sécurité robuste.
Ces trois incidents ont fait les gros titres parce qu’ils sont spectaculaires. Mais ils ne sont pas représentatifs. Le vrai danger du code IA n’est pas le bug évident — celui-là, on le voit, on le corrige, on en fait des conférences. Le vrai danger, c’est le code plausible. Les milliers de lignes parfaitement formatées, parfaitement nommées, parfaitement conformes aux conventions du projet, qui passent les linters et la review parce qu’elles ressemblent à du bon code, et qui s’effondrent dès qu’elles rencontrent un cas limite que l’IA n’avait pas anticipé.
Le code IA mal écrit, on le rejette. Le code IA qui ressemble à du bon code, on le merge. C’est ce mimétisme qui désactive nos détecteurs humains d’anomalies, ces petits signaux d’alerte qu’un dev expérimenté ressent face à une fonction écrite par un junior pressé. Quand l’IA produit, tout est lisse. Et c’est précisément à ce moment-là que notre vigilance baisse.
Les chiffres qui valident cette lecture arrivent maintenant, et ils font mal. Une étude empirique relayée par InfoQ fin 2025, basée sur l’analyse de centaines de milliers de commits sur des dépôts publics, montre que le code généré par IA introduit en moyenne 1,7 fois plus d’issues totales que le code humain. Les erreurs de logique y sont 1,75 fois plus fréquentes, les problèmes de maintenabilité 1,64 fois plus présents, les anomalies de sécurité 1,57 fois plus nombreuses. Plus de 15 % des commits issus d’un assistant IA introduisent au moins un problème détectable.
Sur la sécurité spécifiquement, le GenAI Code Security Report 2025 de Veracode, après analyse de plus de 100 grands modèles, conclut que 45 % du code généré par IA contient au moins une vulnérabilité de sécurité connue. Les classiques — injection SQL, XSS, gestion d’authentification approximative — réapparaissent en masse parce que les modèles ont été entraînés sur du code public, vulnérabilités comprises. Et le volume cumulé de dette technique liée à l’IA, mesuré sur dépôts open-source instrumentés, est passé de quelques centaines d’issues non résolues début 2025 à plus de 110 000 début 2026. Selon les analyses sectorielles, une base de code IA non gouvernée voit ses coûts de maintenance multipliés par 4 dès la deuxième année.
| Indicateur de qualité | Code humain (référence) | Code généré par IA |
|---|---|---|
| Anomalies totales détectées | 1× | 1,7× |
| Erreurs de logique | 1× | 1,75× |
| Problèmes de maintenabilité | 1× | 1,64× |
| Vulnérabilités de sécurité | 1× | 1,57× |
| Coût de maintenance année 2 | 1× | jusqu’à 4× |
Si la notion de dette technique ne vous est pas familière, notre article fait un bon rattrapage avant de poursuivre. Ce qu’on observe en 2026 n’est pas une dette technique normale, c’est une dette d’un genre nouveau, plus difficile à détecter parce qu’invisible aux outils classiques. La définition Wikipédia reste une bonne porte d’entrée. Ma prédiction : les audits techniques de 2027-2028 vont être un carnage. Pas à cause des bugs visibles, mais à cause des milliers de lignes que personne n’a jamais vraiment lues. La nouvelle question d’audit qui devrait s’imposer en 2026, c’est de prendre une fonction au hasard et de demander à son auteur d’expliquer pourquoi telle ligne est là. Si la réponse est floue, vous avez probablement mis le doigt sur de la dette IA invisible.
5. 2026-2028 sera la décennie de la divergence entre équipes — pas de la convergence
Pieter Levels est devenu l’incarnation de ce que beaucoup considèrent comme la promesse ultime de l’IA dans le dev. Solo, sans employé, ~3,5 millions de dollars de revenus annuels, avec des marges supérieures à 90 %. 80 à 95 % de son code est généré ou assisté par IA. Son simulateur de vol multi-joueurs fly.pieter.com, construit en trente minutes avec des outils IA, génère plus de 50 000 dollars par mois en revenus publicitaires. Photo AI, son produit principal, fait 138 000 dollars par mois. Difficile de mieux illustrer ce que l’IA permet à un opérateur ultra-mature, équipé, autonome.
Maintenant, prenez une équipe de quinze développeurs avec une dette technique installée depuis cinq ans, des tests qui couvrent 30 % du code, un CI qui casse trois fois par semaine, et déployez Cursor à tout le monde.
Vous obtenez l’exact inverse.
La vélocité va monter un trimestre, peut-être deux. Et puis le château de cartes va commencer à céder, parce que tout ce qui rendait l’équipe productive avant l’IA — la connaissance partagée du code, les conventions implicites, le temps de relecture, les rituels de mise en prod — va être absorbé par la nouvelle cadence et n’aura pas le temps de s’adapter. Six à douze mois plus tard, l’équipe livre moins, casse plus, et a perdu la mémoire de ce qu’elle a produit récemment.
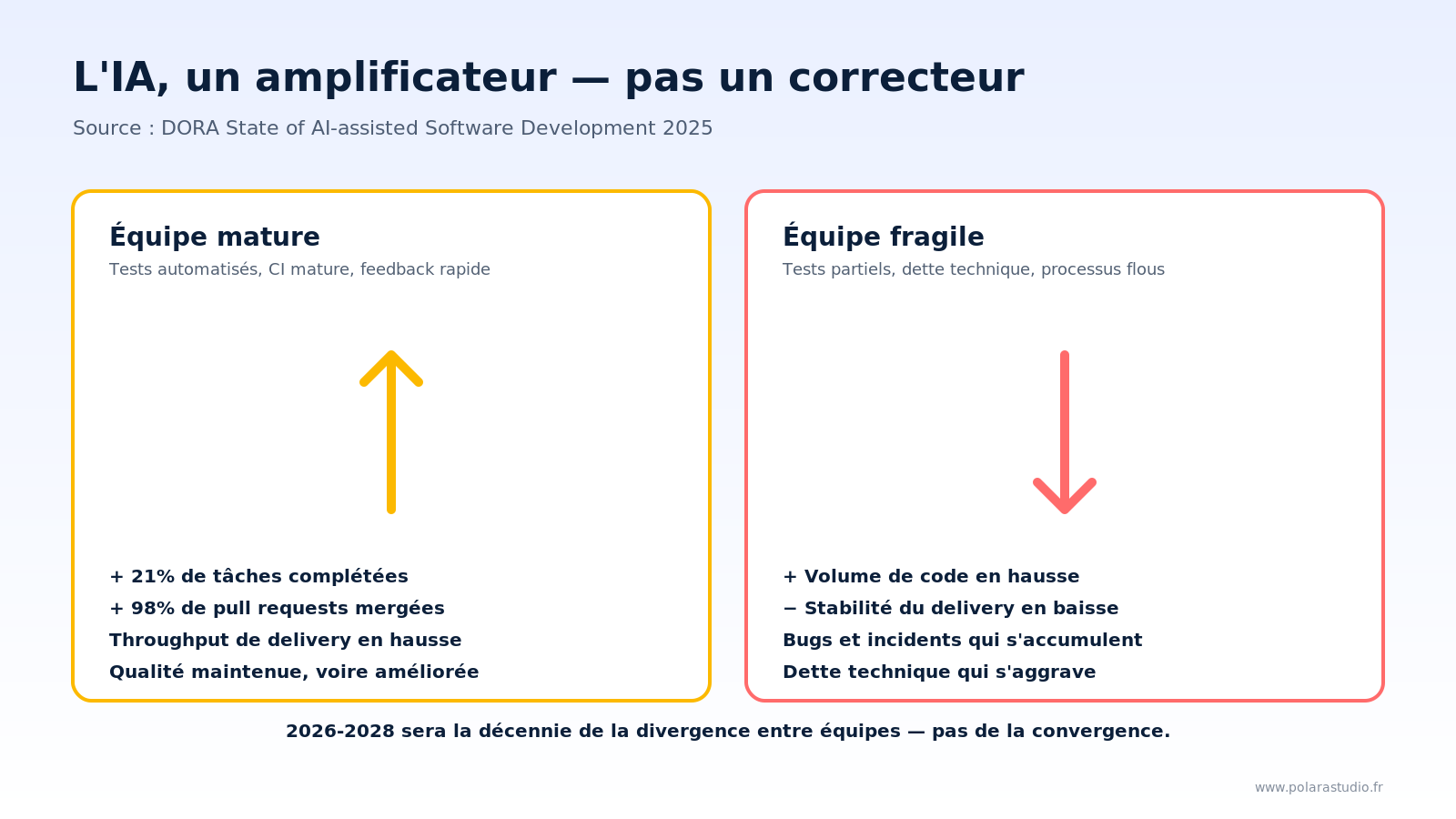
Ces deux scénarios ne sont pas des extrêmes théoriques. Ils sont la même réalité — l’IA comme amplificateur — vue depuis deux points de départ différents. C’est exactement ce que dit le DORA Report 2025, qui est probablement la meilleure étude rigoureuse sur le sujet à ce jour. Plus de 80 % des répondants déclarent que l’IA a amélioré leur productivité individuelle. À l’échelle individuelle, on observe 21 % de tâches en plus et 98 % de pull requests mergées en plus. Mais — et c’est là que tout bascule — les indicateurs de delivery organisationnel restent à plat, et la stabilité du delivery a une corrélation négative avec l’adoption de l’IA. La conclusion littérale du rapport est que « l’IA n’améliore pas une équipe, elle l’amplifie ».
Le rapport identifie sept capacités fondamentales qui amplifient les effets positifs de l’IA : qualité de la documentation interne, accessibilité des données, vélocité du feedback utilisateur, alignement produit-tech, focus sur la valeur livrée, plateformes internes, culture de l’expérimentation. Aucune de ces capacités n’a quoi que ce soit à voir avec l’IA elle-même. Toutes ont à voir avec la maturité de l’organisation. C’est elles qui font la différence — pas le choix de l’éditeur de code. Et c’est exactement pour ça que la décennie qui s’ouvre va creuser des écarts au lieu de les lisser.
Pour mettre ces chiffres dans le contexte plus large des transformations 2026, notre analyse des cinq méga-forces du développement logiciel en 2026 donne une perspective utile. Pour résumer ce que je conseille en consulting : si vous êtes en charge d’une équipe tech qui n’a pas encore investi sérieusement dans la maturité de delivery, l’IA n’est pas votre priorité. C’est même un piège. Votre priorité, c’est ce qui rend l’IA productive — tests automatisés, CI fiable, feedback rapide, documentation vivante. Mettre Cursor dans une équipe sans CI, c’est mettre du carburant haut indice dans un moteur qui fuit.
6. La valeur du développeur va se déplacer vers ce que l’IA ne peut structurellement pas faire — et ce n’est pas du code
Sur scène fin 2025, Amjad Masad, le CEO de Replit, a lâché une phrase qui a beaucoup circulé dans la Valley : « nous ne nous intéressons plus aux codeurs professionnels ». La déclaration était volontairement provocatrice — Replit cherche à embarquer designers, product managers et marketeurs dans la production de logiciels. Elle a été largement relue, et elle est intéressante surtout par ce qu’elle dit en creux. Si Masad peut se permettre de se passer du codeur professionnel, c’est qu’il a fait le pari, à mon sens correct, que la valeur du métier est en train de se déplacer ailleurs. Pas au-dessus, pas au-dessous, ailleurs.
Michael Truell, co-fondateur de Cursor, a fait sensation en racontant sur le podcast de Lenny Rachitsky comment il code au quotidien — au point que la moitié de la communauté dev a, paraît-il, restructuré son workflow dans la semaine. Ce qu’il décrit n’est plus du tout le métier qu’on connaissait il y a trois ans. C’est un travail d’orchestration, de cadrage, de jugement, qui produit dix fois plus de code utile parce qu’il consacre moins de temps à le taper et plus de temps à le diriger. Cette mutation est en train de se généraliser, et elle redéfinit ce qui fait la valeur d’un dev en 2026.
Ce qui disparaît : l’écriture de boilerplate, la mémorisation de syntaxes obscures, la lecture intégrale de la doc d’une bibliothèque pour écrire trois lignes. Ce qui apparaît, ou plutôt ce qui prend une importance disproportionnée : la capacité à formuler un problème, à juger d’une suggestion, à choisir une architecture qui vivra dix ans, à dire non à une feature au bon moment, à comprendre un domaine métier de l’intérieur. Le terme prompt engineering est passé dans les fiches de poste, mais c’est sans doute le plus mal nommé de l’industrie : il ne s’agit pas de bien rédiger, il s’agit de bien cadrer.
Le marché autour de tout ça est devenu colossal. Les assistants de code ont atteint 7,37 milliards de dollars en 2025. L’IA agentique est estimée à 11,55 milliards en 2026 et projetée à 236 milliards d’ici 2034. Replit lui-même a franchi les 100 millions de dollars d’ARR — multiplié par dix en un an.
La grande surprise, contrairement à ce qu’on entendait en 2023 quand les Cassandres annonçaient la mort du métier, c’est que la valeur du vrai développeur n’a jamais été aussi élevée. Plus l’IA monte en puissance sur la production de code, plus la valeur de ceux qui savent juger le code augmente. C’est exactement l’inverse de ce qu’on prédisait. Et c’est une excellente nouvelle pour ceux qui investissent dans la profondeur plutôt que dans la surface.
Pour ceux qui veulent creuser comment ces nouveaux usages s’intègrent dans la construction d’un produit, on a écrit cet article sur la révolution de l’IA dans les SaaS et il y a aussi cet article sur le vibe coding pour l’angle prototypage.
Sur les projets qu’on mène en développement de logiciels sur mesure et en création de SaaS, on a fait évoluer plusieurs choses ces deux dernières années. Plus de temps consacré à la conception et à l’architecture — c’est là que l’humain crée le plus de valeur. Plus de rigueur sur les tests automatisés, les revues de code et l’observabilité — ce sont les garde-fous indispensables quand le volume explose. Et une mesure différente : moins de vélocité brute, plus d’indicateurs de qualité, de stabilité et de valeur produit livrée. Si vous recrutez en 2026, regardez moins le langage maîtrisé et plus la capacité à porter un jugement. Si vous formez vos équipes, investissez moins sur les frameworks et plus sur les fondamentaux d’architecture, de modélisation du domaine métier, de produit. Et si vous êtes développeur, le meilleur conseil que je puisse vous donner : la profondeur, toujours la profondeur.
En guise de conclusion
Ces six lectures ne sont pas indépendantes. Elles racontent la même histoire vue sous six angles. L’IA ne fait pas ce qu’on croit qu’elle fait. Elle ne supprime pas le travail, elle le déplace. Elle ne lisse pas les écarts, elle les amplifie. Elle ne libère pas du jugement humain, elle le rend plus précieux. Et elle ne récompense pas la vitesse aveugle, elle la punit au moment où on s’y attend le moins.
Si je devais résumer en une phrase ce que je vois venir : la période 2026-2028 sera celle où le marché va commencer à distinguer brutalement les équipes qui ont compris l’IA comme un amplificateur de maturité de celles qui l’ont prise pour un correcteur de fragilité. Le tri va se faire vite. Et il sera difficile à inverser une fois enclenché.
Chez Polara Studio, on accompagne au quotidien des startups, des scale-ups et des grands groupes qui veulent construire des SaaS et des logiciels métiers tirant vraiment parti de l’IA — sans hériter de la dette qui va avec. Si l’une de ces six lectures résonne avec ce que vous vivez en ce moment, on est toujours partants pour en discuter.

Écrit par
Jason PindatTech Advisor chez Polara Studio. Expert en architectures logicielles et choix techniques stratégiques.
Tous les articles de cet auteurDécouvrez comment nous intégrons l'IA dans vos produits
Articles similaires

Top 5 des sociétés d'infogérance Cloud en France en 2026
Notre classement 2026 des meilleures sociétés d'infogérance Cloud qu'on recommande à nos clients : Log'in Line, Enix, Claranet, Cyllene, Iguane Solutions.
Lire
SaaSpocalypse : faut-il encore lancer un SaaS en 2026 ?
SaaSpocalypse, 285 milliards effacés, IA qui remplace les apps : faut-il encore lancer un SaaS en 2026 ? La réponse contre-intuitive d'un CEO d'agence.
Lire
Piratage Vercel (Next.js) : la supply chain logicielle vacille à nouveau
Vercel (Next.js) confirme un piratage via un outil IA tiers. Après Axios, la supply chain logicielle inquiète. Décryptage des faits et des risques.
Lire